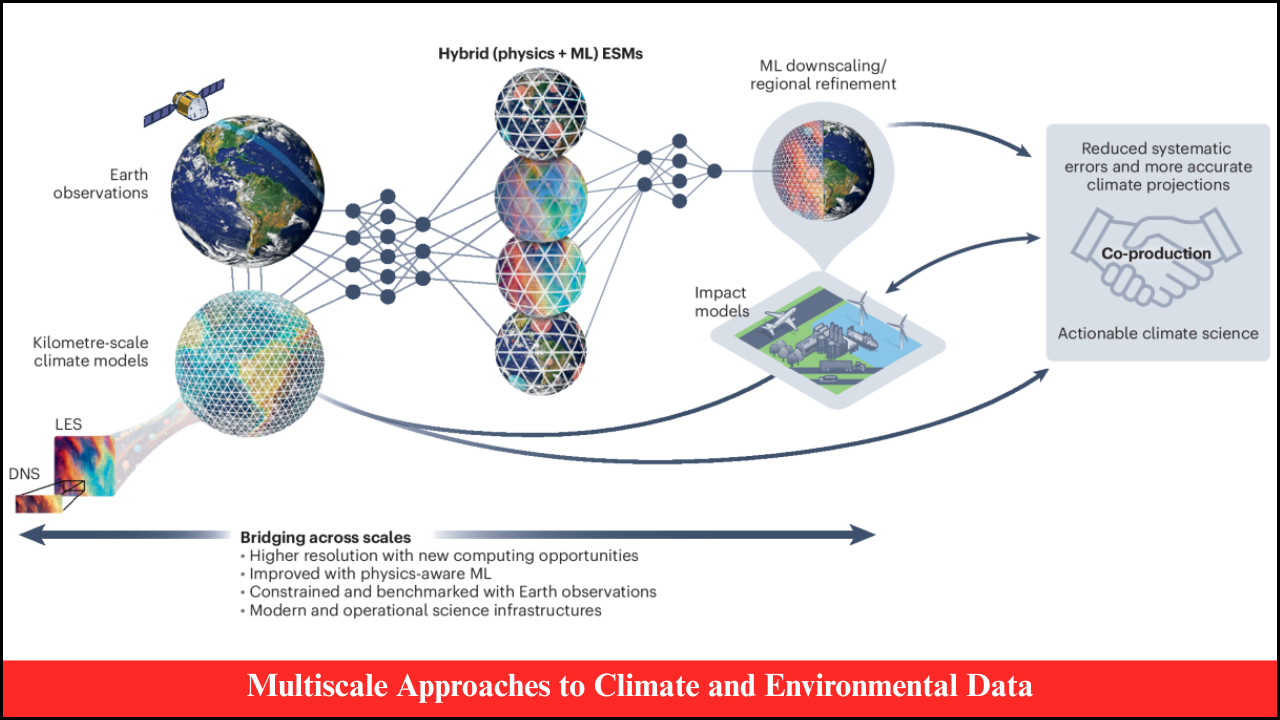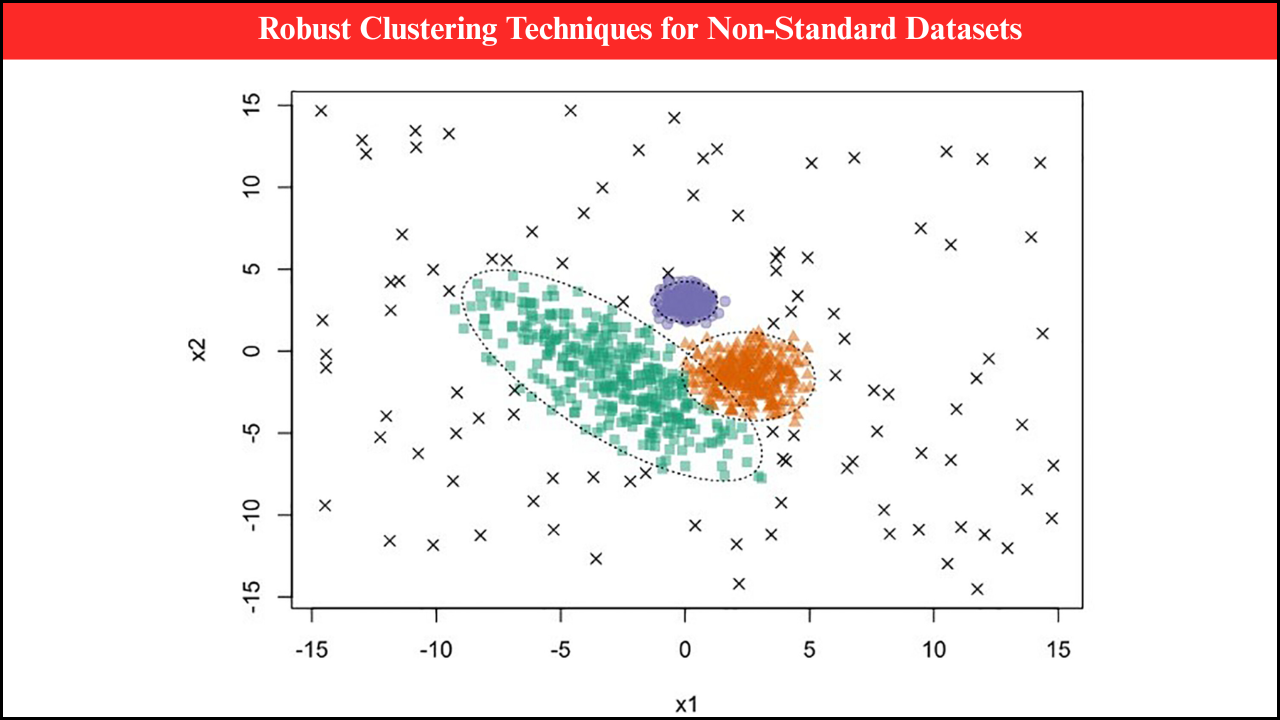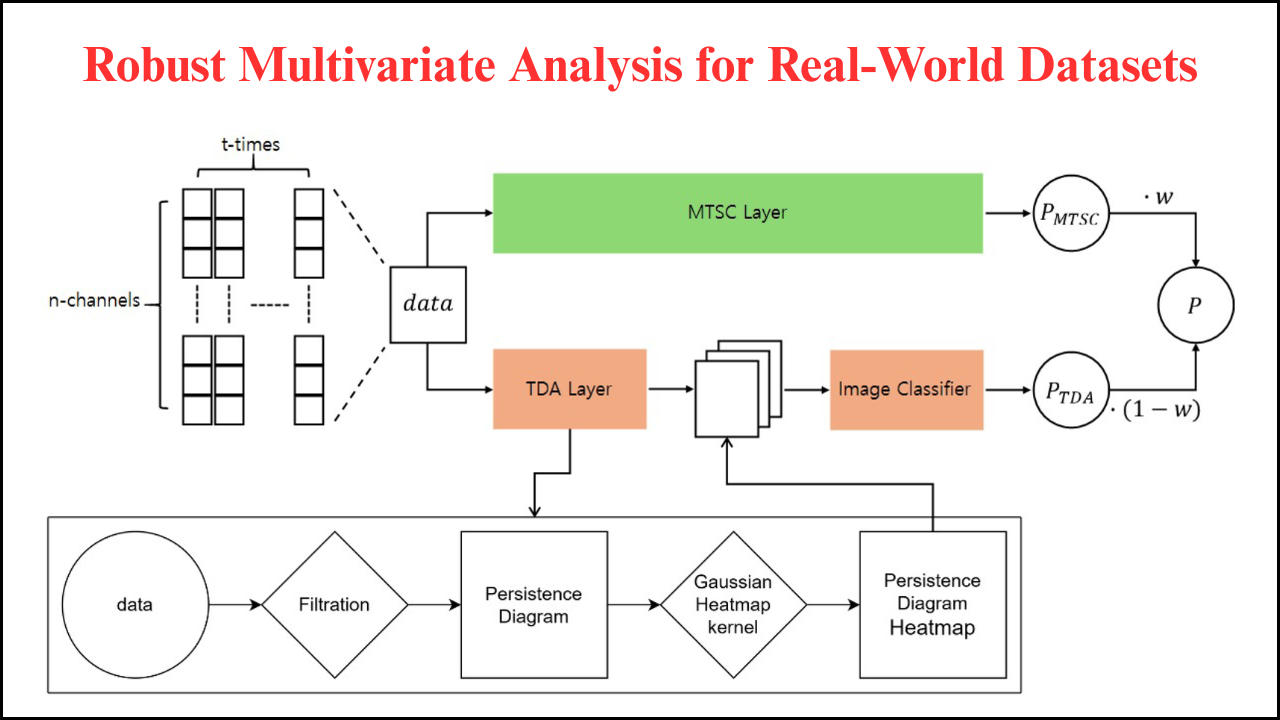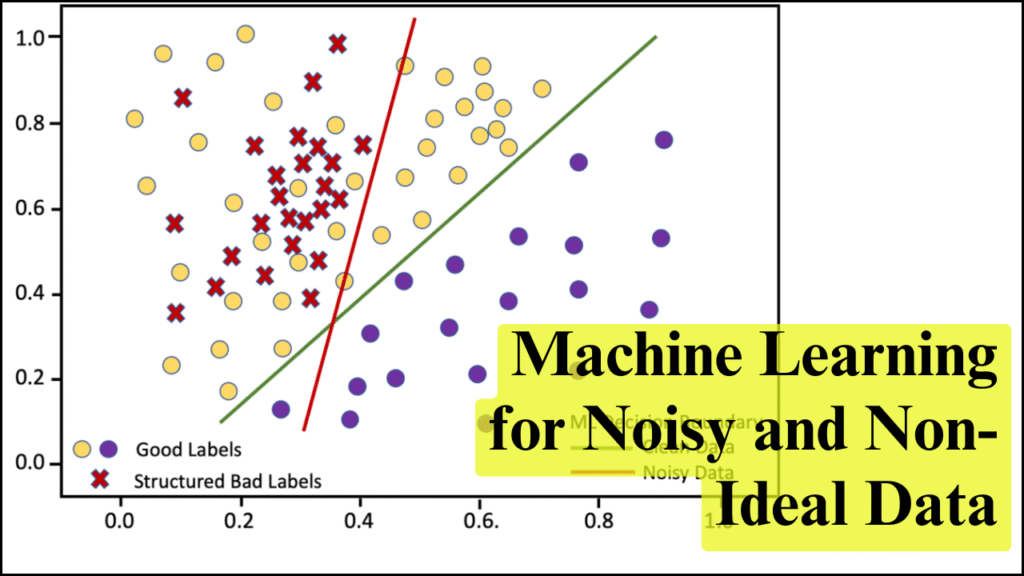
Data in real-world applications is often noisy, incomplete, or non-ideal, posing significant challenges for machine learning (ML) models. Noise can originate from sensor errors, human mistakes, environmental factors, or inconsistencies in data collection. Non-ideal data may include missing values, outliers, skewed distributions, or unbalanced classes. Robust machine learning techniques are designed to handle these imperfections, ensuring reliable predictions and insights even under suboptimal data conditions. Applying such methods is critical in domains like healthcare, finance, climate modeling, and industrial monitoring, where decision-making depends on accurate interpretation of imperfect data.
Table of Contents
Understanding Noisy and Non-Ideal Data
Noisy and non-ideal data refer to datasets that deviate from expected patterns, contain errors, or lack completeness. Common characteristics include:
- Outliers: Extreme values that deviate significantly from other observations.
- Missing Values: Absence of data points due to collection errors or reporting gaps.
- Measurement Errors: Inaccuracies arising from faulty instruments or inconsistent data entry.
- Non-Normal Distributions: Skewed or heavy-tailed data that violate standard ML assumptions.
- Class Imbalance: Unequal representation of categories in classification tasks, leading to biased predictions.
Handling these issues is essential to prevent biased models, overfitting, and poor generalization.
Key Approaches in Machine Learning for Noisy Data
- Robust Preprocessing: Cleaning and transforming data to reduce noise impact. Techniques include outlier detection, normalization, and imputation for missing values.
- Robust Model Selection: Using algorithms less sensitive to data imperfections, such as tree-based methods, ensemble models, and support vector machines with robust kernels.
- Regularization Techniques: Incorporating L1 or L2 penalties to reduce overfitting caused by noisy or irrelevant features.
- Data Augmentation: Artificially expanding datasets through transformations, resampling, or synthetic data generation to improve model robustness.
- Ensemble Methods: Combining multiple models to mitigate the influence of noisy or anomalous data. Examples include Random Forests, Gradient Boosting, and Bagging techniques.
Applications of Machine Learning with Noisy Data
| Application Area | Challenges in Data | ML Approach Used | Outcome |
|---|---|---|---|
| Healthcare Diagnostics | Measurement errors, missing data | Robust regression, ensemble learning | Accurate disease prediction and risk assessment |
| Financial Forecasting | Market volatility, outliers | Robust time series models, ensemble models | Stable stock and risk predictions |
| Climate Modeling | Sensor noise, incomplete records | Random Forests, Robust PCA | Improved climate trend and extreme event detection |
| Industrial Monitoring | Sensor faults, noisy readings | Autoencoders, anomaly detection | Reliable fault detection and maintenance planning |
| Image and Signal Processing | Noise in images or sensor signals | Convolutional Neural Networks (CNN) with noise augmentation | Enhanced recognition and classification accuracy |
Techniques for Handling Noisy Data
- Robust Regression: Methods like M-estimators and Huber regression reduce sensitivity to outliers in regression tasks.
- Tree-Based Models: Decision trees and ensembles such as Random Forests or XGBoost are inherently robust to noisy inputs and missing values.
- Support Vector Machines (SVM): SVMs with soft margins or robust kernels handle mislabeled or noisy data effectively.
- Autoencoders and Denoising Networks: Neural networks trained to reconstruct clean input from noisy data are widely used in image and signal processing.
- Data Imputation Techniques: Strategies like k-nearest neighbors (KNN) imputation, multiple imputation, or model-based approaches fill missing values while preserving data structure.
- Outlier Detection and Removal: Methods such as Local Outlier Factor (LOF), Isolation Forest, and statistical thresholding help identify and manage anomalies.
Case Studies Demonstrating Robust ML Applications
| Case Study | Dataset Type | ML Technique Used | Result |
|---|---|---|---|
| Predicting Patient Outcomes | Clinical measurements | Random Forest, Robust Regression | Accurate predictions despite missing and noisy data |
| Stock Price Forecasting | Historical market data | ARIMA with robust preprocessing, Ensemble models | Stable forecasts despite volatile trading data |
| Weather Forecasting | Sensor networks, satellite data | Random Forests, Robust PCA | Improved prediction of rainfall and temperature trends |
| Industrial Equipment Monitoring | Sensor readings, operational logs | Autoencoders, Anomaly Detection | Early fault detection with minimal false alarms |
| Image Recognition | Noisy medical imaging | Denoising CNNs | High accuracy classification despite noise |
Advantages of Machine Learning for Noisy Data
- Improved Accuracy: Robust techniques ensure predictions are less affected by anomalies.
- Enhanced Generalization: Models perform better on unseen data despite imperfections.
- Flexibility: Applicable across domains, including healthcare, finance, climate, and industrial monitoring.
- Early Detection of Issues: Capable of identifying anomalies, extreme events, or system failures in advance.
Challenges in Applying Robust ML Techniques
- Computational Requirements: Robust models, especially ensembles and deep networks, require substantial computing resources.
- Model Complexity: Incorporating robustness often increases model complexity, making interpretation difficult.
- Data Quality Limitations: Extremely noisy or sparse datasets may still challenge even robust algorithms.
- Hyperparameter Tuning: Robust methods often require careful tuning to achieve optimal performance.
Technological Tools Supporting Robust ML
- Python Libraries: scikit-learn, TensorFlow, PyTorch, and statsmodels offer robust modeling and preprocessing functions.
- High-Performance Computing (HPC): Essential for training large neural networks on noisy datasets.
- Cloud Platforms: Services like AWS, Azure, or Google Cloud provide scalable resources for robust ML implementations.
- Data Pipelines and Automation: Tools like Apache Airflow or MLflow help manage preprocessing, model training, and evaluation on noisy data.
Future Directions in Machine Learning for Noisy and Non-Ideal Data
- Hybrid Approaches: Combining robust statistical models with deep learning for better noise handling.
- Adaptive Learning: Models that dynamically adjust to changing noise patterns or missing data during deployment.
- Explainable AI (XAI): Developing interpretable, robust models to understand the influence of noise and outliers.
- Cross-Domain Applications: Extending robust ML techniques to more real-world scenarios, including IoT, autonomous systems, and climate resilience.
- Integration with Real-Time Data: Implementing robust ML in streaming data applications for immediate anomaly detection and forecasting.
Parting Insights
Machine learning for noisy and non-ideal data is a critical area of research and application. By incorporating robust preprocessing, adaptive models, and ensemble techniques, ML systems can deliver accurate predictions and insights even under imperfect data conditions. These methods enhance decision-making in finance, healthcare, climate science, industrial monitoring, and other high-stakes domains. As computational resources, algorithms, and data availability continue to advance, robust machine learning approaches will play an increasingly central role in extracting actionable insights from real-world, noisy datasets.