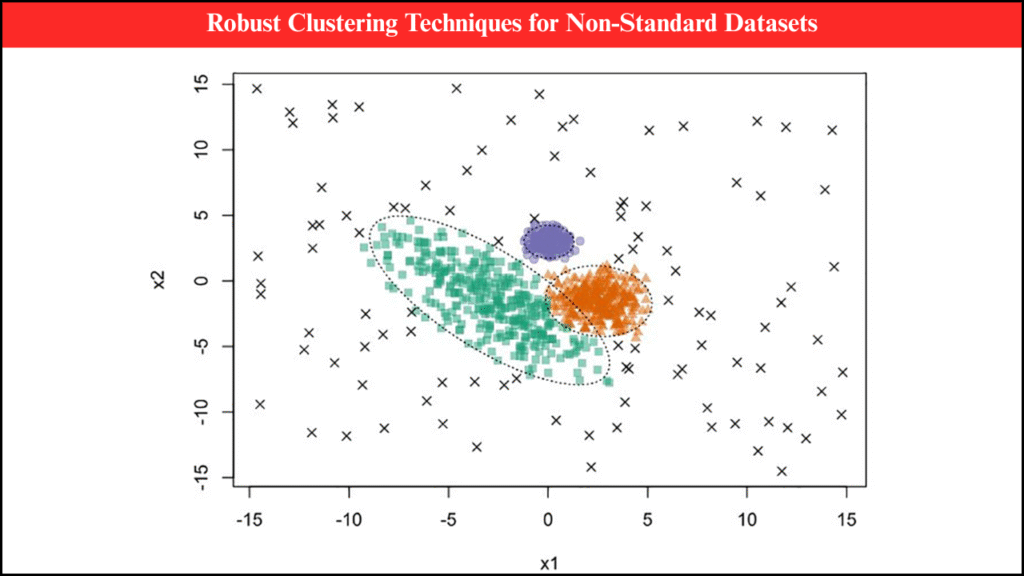
Data in real-world scenarios often deviates from standard assumptions of uniformity, normality, or completeness. Non-standard datasets may include outliers, missing values, skewed distributions, or mixed data types, making traditional clustering methods unreliable. Robust clustering techniques address these challenges by providing accurate grouping and pattern recognition even when datasets are irregular or noisy. These techniques are essential across diverse fields such as healthcare, finance, climate science, marketing, and social network analysis. Robust clustering enhances decision-making, improves data interpretation, and ensures reliable insights from imperfect data.
Table of Contents
Understanding Non-Standard Datasets
Non-standard datasets are characterized by:
- Outliers: Extreme values that deviate from the general data distribution.
- Noise: Random or systematic errors in measurements.
- Missing Data: Incomplete entries in records, often due to collection errors.
- Mixed Data Types: Combination of categorical, ordinal, and numerical attributes.
- High Dimensionality: Large numbers of features that complicate clustering.
- Skewed or Heavy-Tailed Distributions: Data that violates assumptions of standard clustering algorithms.
Clustering such datasets requires robust techniques that minimize sensitivity to irregularities while accurately identifying underlying patterns.
Key Components of Robust Clustering
- Outlier Resistance: Algorithms limit the influence of extreme observations on cluster formation.
- Noise Handling: Methods are designed to tolerate random or systematic data errors.
- Flexibility in Data Types: Capable of handling numerical, categorical, or mixed-type attributes.
- Adaptability to High Dimensionality: Techniques that maintain performance even with many features.
- Automatic Determination of Cluster Numbers: Algorithms that can infer the optimal number of clusters without prior assumptions.
Applications of Robust Clustering
| Application Area | Data Challenge | Robust Clustering Technique | Outcome |
|---|---|---|---|
| Healthcare Patient Segmentation | Mixed lab results and outliers | k-Medoids, DBSCAN | Accurate grouping of patients for personalized care |
| Financial Market Analysis | Noisy transaction data | Robust hierarchical clustering | Identification of trading patterns and anomalies |
| Climate Data Analysis | Missing and irregular measurements | Density-based clustering (DBSCAN, OPTICS) | Detection of climate regions and weather patterns |
| Social Network Analysis | Large, sparse networks | Spectral clustering with robust preprocessing | Identification of communities and influencers |
| Marketing Customer Segmentation | Skewed purchase behavior | Fuzzy c-Means with robust distance metrics | Improved targeting and segmentation strategies |
Popular Robust Clustering Techniques
- k-Medoids: A variation of k-Means that selects actual data points as cluster centers (medoids) rather than means, reducing sensitivity to outliers.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Group data points based on density, identifying outliers as noise, and is effective for irregularly shaped clusters.
- OPTICS (Ordering Points To Identify the Clustering Structure): Handles varying cluster densities and identifies meaningful cluster structures in non-standard datasets.
- Robust Hierarchical Clustering: Agglomerative or divisive clustering approaches with robust linkage criteria that minimize the influence of outliers.
- Fuzzy c-Means with Robust Distance Metrics: Allows soft clustering where points can belong to multiple clusters, using distance metrics that are less sensitive to extreme values.
- Spectral Clustering with Robust Preprocessing: Uses eigenvectors of a similarity matrix for clustering, often combined with preprocessing techniques that handle missing values and noise.
Case Studies of Robust Clustering in Non-Standard Data
| Case Study | Dataset | Technique Used | Result |
|---|---|---|---|
| Patient Risk Profiling | EHR with outliers and missing labs | k-Medoids | Identified patient subgroups for targeted interventions |
| Stock Market Anomaly Detection | Transaction and price data | DBSCAN | Detected abnormal trading patterns and anomalies |
| Climate Region Classification | Satellite temperature and rainfall | OPTICS | Revealed distinct climate zones with minimal preprocessing |
| Social Media Community Detection | Sparse social network connections | Spectral clustering with robust similarity | Mapped influential communities and detected network clusters |
| Customer Segmentation in Retail | Skewed purchase and demographic data | Fuzzy c-Means with robust distances | Improved targeting for marketing campaigns |
Advantages of Robust Clustering Techniques
- Resilience to Outliers: Clusters are not dominated or distorted by extreme observations.
- Flexibility Across Domains: Applicable to healthcare, finance, climate, marketing, and social networks.
- Effective Noise Handling: Differentiates between meaningful clusters and noise.
- Capability with Mixed Data Types: Can process categorical, ordinal, and numerical data simultaneously.
- Adaptability to Complex Structures: Identifies irregularly shaped clusters that traditional methods may fail to detect.
Challenges in Robust Clustering
- Computational Complexity: Some algorithms, especially for large datasets, require significant processing power.
- Parameter Selection: Methods like DBSCAN and fuzzy c-Means require careful selection of parameters (e.g., epsilon, fuzziness) to ensure meaningful clusters.
- Interpretability: Clusters may require additional analysis to explain patterns to stakeholders.
- Scalability: High-dimensional or massive datasets can challenge even robust algorithms without preprocessing or dimensionality reduction.
Technological Tools Supporting Robust Clustering
- Python Libraries: scikit-learn, PyClustering, and HDBSCAN provide implementations of robust clustering algorithms.
- R Packages: cluster, fpc, and dbscan packages offer robust clustering capabilities with visualizations.
- High-Performance Computing (HPC): Enables the processing of large, complex, and high-dimensional datasets efficiently.
- Data Preprocessing Platforms: Tools for outlier removal, normalization, and missing data imputation enhance the effectiveness of robust clustering.
Future Directions in Robust Clustering for Non-Standard Data
- Hybrid Clustering Approaches: Combining multiple clustering techniques (e.g., density-based + hierarchical) for improved robustness.
- Integration with Machine Learning: Using clustering results as features for supervised learning models to improve prediction accuracy.
- Adaptive Clustering: Developing algorithms that dynamically adjust parameters based on dataset characteristics.
- Visualization Techniques: Improved visualization methods for high-dimensional robust clustering to aid interpretation.
- Real-Time Clustering: Applying robust methods to streaming data in finance, healthcare, or IoT applications for immediate insights.
Wrapping Up
Robust clustering techniques provide reliable solutions for non-standard datasets that are noisy, incomplete, or irregularly distributed. By mitigating the influence of outliers, handling missing data, and adapting to mixed or high-dimensional data, these techniques ensure accurate pattern recognition and meaningful group identification. Case studies in healthcare, finance, climate science, marketing, and social networks demonstrate the practical utility of robust clustering. As computational tools, algorithms, and hybrid approaches advance, robust clustering will continue to play a pivotal role in extracting actionable insights from complex and imperfect real-world datasets.